
Nedávno jsme při debatě nad programováním narazili na to, že spoustu vývojářů neví jak pracovat s GITem. Tedy, rozumí základním příkazům, umí udělat commit, zamergovat do „master“ větve a tím to celé končí. Pojďme se společně podívat GITu trochu pod pokličku – začneme základy co to GIT je, ukážeme si základní příkazy a budeme se věnovat i pokročilejším věcem (interaktivní rebase, squashování commitů apod.). Řekneme si o tom, co v rámci GITu trackovat a co naopak ne.
Co je GIT?
Pokud s GITem už trochu pracujete, můžete tuto část klidně přeskočit. GIT je systém pro verzování našich aplikací. Co to znamená v praxi? Moje začátky v programování fungovaly tak, že jsem si založil projekt, programoval a po čase, když jsem si myslel, že je featura hotová, jsem prostě soubory zkopíroval někam na FTP a tím to pro mě bylo hotovo. Problém nastal v případě, že jsem vyvíjel nějakou funkcionalitu a najednou se v produkci objevil bug. Potřeboval jsem všeho nechat, opravit chybu a pak se vrátit tam, kde jsem při vývoji feature skončil.
Takovýto problém se dá řešit například tím, že si zkopíruju složku s projektem, „zazálohuji“, stáhnu složku s kódem z produkce, opravím chybu, nahraju na produkci, zkopíruju ze „zálohovací“ složky projekt zpět a můžu vyvíjet. (ideálně ještě zapracuji změny z hotfixu na produkci, abych tam poté chybu znovu nevypustil). Zní to složitě? Taky že je! A ještě k tomu náchylné na chyby. Při představě, že budu takových funkcionalit vyvíjet více najednou nebo bych na projektu vyvíjel s více vývojáři… Je mi zle 😀
Jak GIT funguje?
Vytvoříme složku a vytvoříme náš první soubor, do kterého něco zapíšeme. Když jsme s výsledkem spokojeni, uděláme commit. Commit je vlastně pojmenovaná změna, přičemž v jednom commitu můžeme změnit i více souborů. Soubory můžeme přidávat, mazat, přesouvat nebo upravovat. Netýká se to pouze textových souborů – GIT ukládá soubory binárně, takže můžeme trackovat i obrázky.
Poté soubor změníme, přidáme řádku a opět commitneme. Budou tedy dva commity a v detailu každého commitu uvidíme přesně ty změny, které jsme udělali.
Většina verzovacích systémů funguje na principu sledování změn, zatímco GIT funguje na principu „snímků“ všech souborů, které sledujeme. Commitneme-li nový soubor, GIT se podívá na jeho obsah, podívá se na to kdo soubor vytvořil, zjistí jeho oprávnění (chmod), čas poslední změny a jiná další metadata. Tyto informace uloží a informaci o souboru opatří kontrolním hashem který zajistí, aby soubor nikdo bez našeho vědomí nezměnil. Toto se děje s každým souborem. Pokud dále commitujeme změny v jiných souborech, GIT si udělá „snímek“ všech souborů v repozitáři. Aby vše bylo efektivnější, u souborů které se nezměnili se GIT pouze odkáže na poslední verzi souboru skrze hash.
Podobně je to s celým commitem, který také obsahuje kontrolní hash. Commit v sobě obsahuje kromě samotných změn i další metadata – kdo commit vytvořil, čas kdy byl commit zapsán a popis commitu. Také obsahuje hash, který odkazuje na předchozí commit (nebo commity v případě mergování) tak, aby byla zajištěná kontinuita a bezpečnost. To znamená, že v případě, kdy někdo změní nějaký commit v historii, změní se i všechny následující commity až do současnosti.
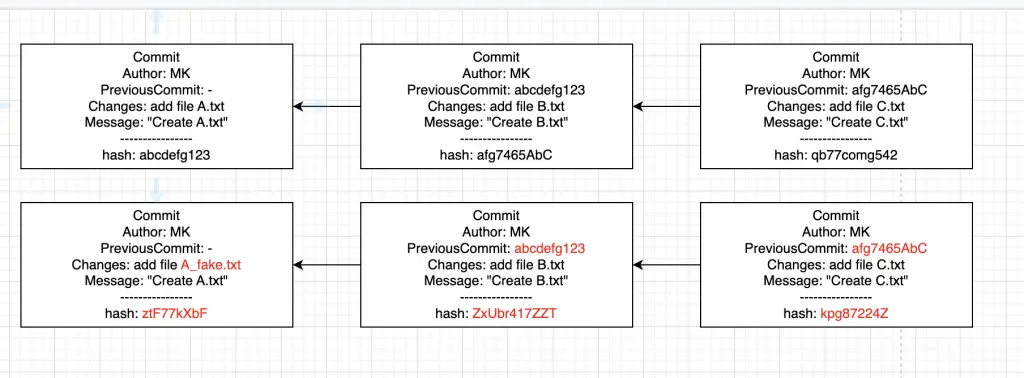
Tuto situaci jsem znázornil v následujícm obrázku. První řádek ilustruje poslední 3 commity z nějakého repozitáře. Nejdříve jsem vytvořil soubor A.txt, poté B.txt a nakonec C.txt. Můžeme vidět, že každý commit obsahuje i odkaz na předchozí commit. V druhé řádce pak někdo modifikoval první commit tak, že soubor A.txt přejmenoval na A_fake.txt. Vidíme, že se okamžitě změnil hash commitu, načež se změnili všechny následující commity. Pro změnu hashe by uživatel nemusel změnit nutně soubor, stačilo by i kdyby přidal jednu mezeru navíc do commit message a výsledek by vypadal stejně.
Working directory, staging area, repository
Při práci s GITem rozlišujeme 3 stavy, ve kterém se změna může nacházet.
Working directory
Tento základní stav obsahuje změny, které jsme v souborech provedli a nic jsme s nimi zatím v kontextu GITu neudělali.
Staging area
Tento stav obsahuje soubory, které chceme commitovat. Pokud chceme soubor přesunout do tohoto stavu, můžeme to udělat pomocí příkazu git add, pokud ho chceme vrátit zpět použijeme příkaz git reset.
$ git add <název souboru/adresář/nic pro všechny soubory>
$ git reset <název souboru/adresář/nic pro všechny soubory>
Po vytvoření souboru, kdy je soubor ve working directory to vypadá nějak takto.
Changes to be committed:
(no files)
Changes not staged for commit:
(no files)
Untracked files:
? A.txt
Soubor je nový, není zatím trackován. Pokud bych už soubor trackovaný měl a jednalo by se pouze o změnu, bude výsledek vypadat takto:
Changes to be committed:
(no files)
Changes not staged for commit:
M A.txt
Untracked files:
(no files)
Po přesunutí souboru do staging area bude výsledný stav vypadat takto:
Changes to be committed:
M A.txt
Changes not staged for commit:
(no files)
Untracked files:
(no files)Jak z ukázky vyplývá, pokud bych teď zadal příkaz git commit, vytvoří se nový commit ze všech souborů, které jsou aktuálně ve staging area (viz. Changes to be commited)
Základní příkazy
Dost bylo teorie, pojďme na praxi. Pro názornost budu používat příkazovou řádku, jelikož je univerzální a případně addon TIG (http://jonas.github.io/tig/), což je takové primitivní GUI v konzolové řádce, které mi usnadňuje práci.
Pojďme si nasimulovat příklad, který byl znázorněn v předchozím obrázku.
$ mkdir git-sample # vytvoření adresáře
$ cd git-sample # přepnutí se do nově vytvořeného adresáře
$ git init # samotná inicializace gitu
$ touch A.txt # vytvoření souboru
$ git add . # přidání souboru do stagingu
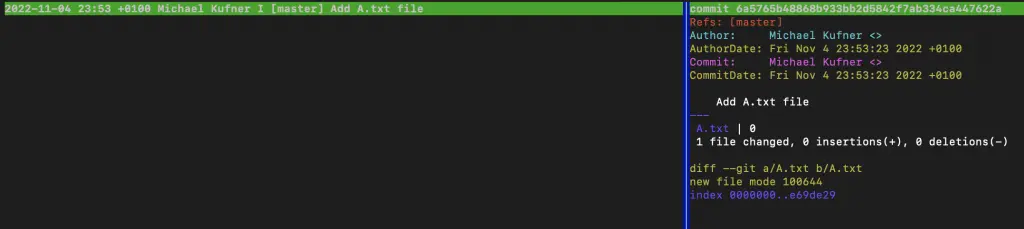
$ git commit -m "Add A.txt file" # vytvoření commitu s popisem
Vytvořili jsme první commit. Pokud bych se u popisu commitu chtěl rozepsat, můžu příznak -m vynechat a GIT mi poté otevře textový editor, kde si mohu napsat třeba celou esej :-). Po zadání příkazu tig se můžu podívat na celou GIT historii, interaktivně si procházet jednotlivé commity.
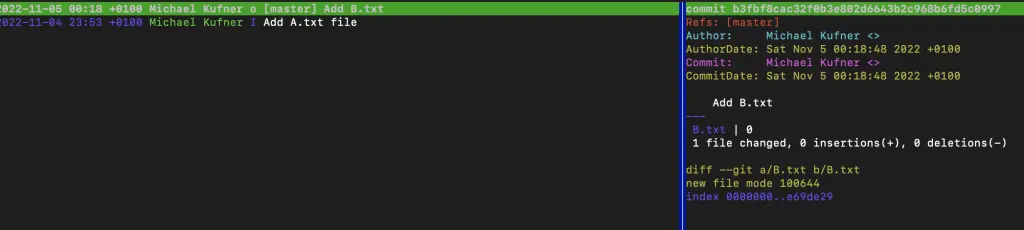
Vytvoříme si i další soubor B.txt a podíváme se, jak bude situace vypadat.
Může se stát, že si svojí změnu i po nacomittování rozmyslím. V tom případě mohu commit smazat. Pokud nepoužiji přepínač hard, změny nám v souboru zůstanou. Pouze se změní jejich stav v rámci GITu a o změny tak nepřijdu.
$ git reset HEAD~1
$ git reset HEAD~1 --(hard/soft/mixed)Tímto způsobem se dá smazat i více commitů najednou, stačí upravit číslo za tildou (~). Je však pravidlem, že se commity mažou od nejnovějšího po nejstarší. Pokud bych chtěl smazat pouze jeden commit v historii, musel bych použít tzv. interaktivní rebase, o kterém si řekneme později. Git reset v podstatě resetuje GIT o X commitů zpět.
Možnosti příkazu „git reset“
Příkaz git reset má několik dalších možností, které se mohou hodit.
- soft – změny, které jsme „vymazali“ nám zůstanou ve staging area. Jsou tak hned připravené ke commitování.
- mixed – změny, které jsme „vymazali“ budou po zadání příkazu ve stavu working directory.
- hard – změny které jsme „vymazali“ se zároveň smažou i v souboru. To znamená, že o změny přijdu. Pokud bych tento přepínač uvedl omylem, dá se to pomocí práce s git reflog ještě zvrátit.
Commit ammending
V případě, že chceme přidat nějaké změny do commitu, který jsme udělali jako poslední, není třeba poslední commit resetovat a následně commitovat znovu. Stačí využít přepínač ammend u příkazu commit. Ten nám udělá to, že namísto vytvoření nového commitu se změny přidají do posledního vytvořeného commitu.
$ git commit --amendVětve a mergeování
Větve jsou užitečné zejména v situacích, kdy na projektu pracuje více vývojářů. Každý nově vytvořený repozitář má jako svou výchozí větev větev master (případně main, záleží na konvenci). Každý vývojář si může vytvořit svojí větev (nebo dokonce více větví, pro každou funkcionalitu zvlášť), vyvíjet nezávisle na ostatních. A pokud je s prací hotov, práci zamerguje do tzv. masteru, kde pak na jeho práci mohou další vývojáři navázat. Pojďme si tuto situaci znázornit.
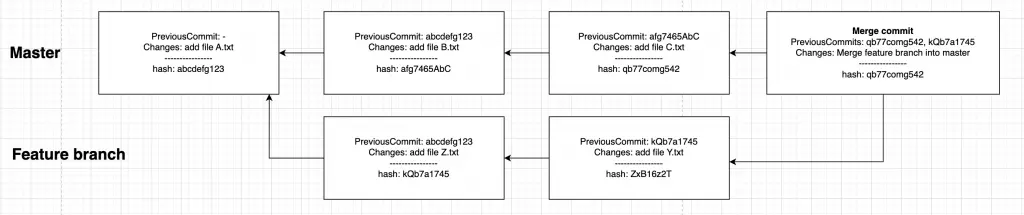
V této situaci byl v masteru jeden commit, který přidává soubor A.txt. Poté si vývojář založil svoji větev, kdy přidal soubory Z.txt a Y.txt. Mezitím však v masteru přibyly další commity (vytvoření souboru B.txt a C.txt). Poté se vývojář rozhodl svoji větev zamergovat do masteru. Master nyní obsahuje soubory A.txt, B.txt, C.txt, Z.txt a Y.txt.
Jak z commitu GIT pozná že je to merge commit a jak pozná, že se založila nová větev? Pomocí parent hashů (viz. znázornění):
- Merge commit: Má 2 parent hashe namísto 1
- Rozdělení větví: Commit je parentem dvou commitů, tzn. první commity z každé větve mají stejný parent hash
Příkazy pro práci s větvemi
$ git branch # seznam větví, aktivní větev je zvýrazněna
$ git checkout -b # vytvoření nové větve, do které se ihned přepneme
$ git checkout # přepínání mezi již existujícími větvemi
$ git branch -D # smazání větve Mergeování
Pro merge větve slouží příkaz git merge. Je důležité si uvědomit, že musíme mít aktivní větev, do které mergujeme (být v ni „checkoutnutý“). Pro ilustraci si ukážeme situaci, kdy má vývojář aktivní branch, ve které zrovna vyvíjí a chce zamergovat tuto svoji větev do masteru.
$ (git: feature): git checkout master # přepneme se do masteru
$ (git: master): git merge featurePo zadání těchto příkazů se nám otevře textový editor (podobně jako při commitování bez přepínače -m). Po uložení dojde k zamergeování. Výsledek vycházející z výše uvedeného diagramu by mohl vypadat nějak takto:

Rebasování
Rebase je důležitá součást GITu. Zůstaneme u předchozího případu u mergeování. Situace vypadá stejně – vývojář si založil svojí větev a v ní vyvíjí nějakou svojí funkcionalitu (vývoj souborů Y.txt a Z.txt). Mezitím v masteru přibydou soubory B.txt a C.txt a součástí funkcionality, kterou vývojář ve své větvi vývijí je i úprava souboru B.txt. Ten ale zatím ve své větvi nevidí. Co s tím? Řešením je rebase. Důležité si je opět uvědomit, že upravuju feature větev, kterou chci rebasnout nad master. Čili musím mít aktivní feature branch.
$ (git: master): git checkout feature
$ (git: feature): git rebase masterUkážeme si to na následujícím schématu. Před rabasem situace vypadá takto:
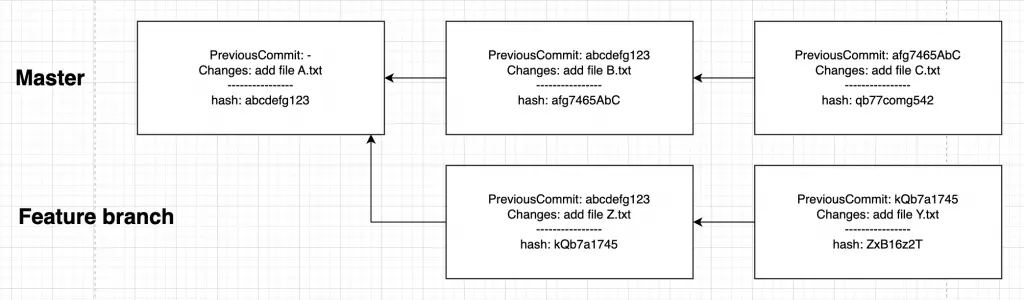
Po rebasu vypadá situace takto:

Povšimněme si červeně zvýrazněných změn – změnily se nám hashe již vytvořených commitů. Tím, že se změnil předek prvního commitu v naší feature branchy, změnil se i hash tohoto commitu. A to samé se děje pro všechny následující commity v naší branchy. Až dojde řeč na pushování větví do repozitáře na serveru, bude nás to, že se změnila historie commitů v naší větvi zajímat.
Fast forward merge
Větve fungují tak, že každá větev ukazuje na poslední commit v dané větvi. To je důležité pro pochopení rozdílu mezi fast-forward a 2/3-way mergováním.
Pokud bych se teď rozhodl stejně jako v předchozí ukázce zamergovat svojí větvi, dojde k tzv. fast-forward mergy. To znamená, že zamergováním větví nevznikne merge commit, ale místo toho se pouze aktualizuje ukazatel master větve. Před mergem ukazatel master větve směřoval na commit s hashem „afg7465AbC“. Po fast-forward mergování se tento ukazatel změní na „UkQ7cbA123“ a historie bude pak vypadat následovně:
$ (git: master): git merge feature

Pokud bych toto z nějakého důvodu nechtěl, mohu využít přepínače, který tento fast-forward merge zakáže a „vyrobí“ se klasický merge commit.
$ (git: master): git merge feature --no-ff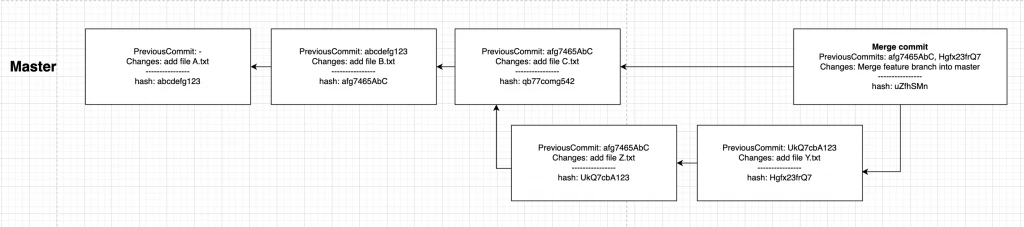

Je vidět, že v obou případech s rebasem je GIT historie o něco „hezčí“. Dost často bývají oba způsoby součástí programátorské kultury. Na některých projektech existují pravidla, že feature větev se před zamergováním nejprve rebasne a poté se provede fast-forward/2-way merge. Který z nich, to záleží na dohodě, co komu přijde „hezčí“ 🙂
Cherry-pick
Představme si situaci, kdy jako vývojář mám 2 feature větve a v obou vyvíjím dvě odlišné funcionality. První funkcionalitou je přidání souborů A.txt a B.txt. Druhou funkcionalitou je přidání souboru X.txt a zároveň úprava souboru A.txt, který si vyvíjím ve své první větvi. Jde to samozřejmě opět vyřešit rebasem, ale v tom případě budu mít celou svoji druhou větev založenou na své první, což ne vždy chci. Řešením je cherry-pick, který mi umožní „zkopírovat“ commit z první větve do druhé.
$ git cherry-pick <hashCommitu>
$ (git: feature2): git cherry-pick kQb7a1745Před cherry-pickem vypadá situace takto:
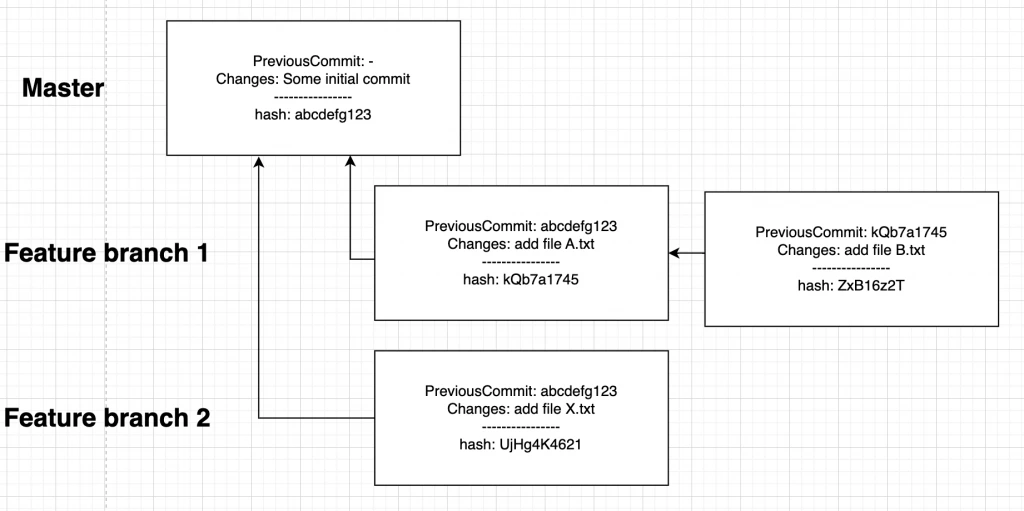
Po cherry-picku vypadá situace takto:
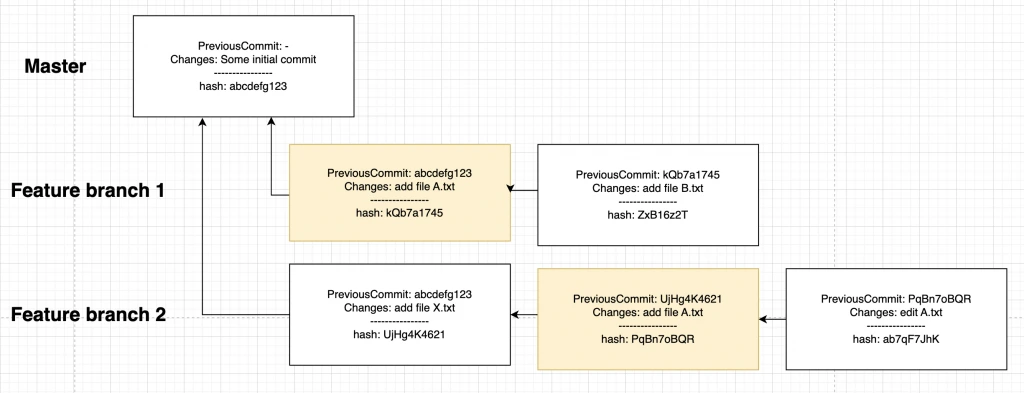
Povšimněte si zvýrazněných commitů. Jsou totožné (obsahem), ale hashe se liší, protože ačkoli mají stejný obsah, liší se jejich předek.
Interaktivní rebase
Interaktivní rebase se hodí v situacích, kdy chceme měnit historii repozitáře. K tomu můžeme mít více důvodů:
- chceme smazat commit, který není poslední a nechceme mazat „od nejnovějšího“
- chceme upravit obsah commitu v historii
- chceme upravit popis commitu v historii
- chceme nějaké změny co jsme udělali přidat do již existujícího commitu, který není poslední
- chceme více commitů „squashnout“ (zamergovat) do jednoho
- chceme změnit pořadí commitů
Základem je následující příkaz, který nám otevře textový editor, ve kterém poté provádíme změny. Číslo označuje počet commitů do historie, u kterých chceme interaktivní rebase provést. Je důležité si uvědomit, že interaktivním rebasem měním historii GITu.
$ git rebase -i HEAD~3Smazání commitu z historie
Mějme situaci, kdy ve větvi máme 3 commity – jeden vytváří soubor A.txt, druhý B.txt a třetí C.txt. Uvědomíme si, že soubor B.txt je zbytečný a tak se ho rozhodneme smazat.

Použijeme interaktivní rebase.
$ git rebase -i HEAD~3Po zadání se nám otevře textový editor, který vypadá takto:
pick 90b08a2 Add A.txt file
pick a2ef353 Add B.txt file
pick 848ddfa Add C.txt filePro smazání commitu se souborem B.txt (a tedy i k jeho reálnému odstranění) smažu řádku č. 2. a soubor uložím.
pick 90b08a2 Add A.txt file
pick 848ddfa Add C.txt filePo uložení bude chybět nejenom commit se souborem B.txt, ale i soubor samotný.


Úprava popisu commitu v historii
Mějme úplně stejnou výchozí situaci jako v předchozím případě. S tím rozdílem, že místo smazání commitu přidávajícího soubor B.txt budu chtít u tohoto commitu změnit jeho popis. Po zadání stejného příkazu se mi opět otevře textový editor.
pick 90b08a2 Add A.txt file
pick a2ef353 Add B.txt file
pick 848ddfa Add C.txt fileMísto smazání řádky přepíšu slovo „pick“ na slovo „reword“. Stačí i zkratka „r“.
pick 90b08a2 Add A.txt file
r 1c70d1c Add B.txt file
pick 8657336 Add C.txt filePo uložení se mi znova otevře editor, tentokrát s původní hláškou.
Add B.txt fileTuto hlášku libovolně upravím a uložím.


Změna pořadí commitů
Postup je úplně stejný jako v předchozích případech. Jediný rozdíl je v tom, že prohodím řádky a po uložení budou commity v pořadí, v jakém jsem si zvolil.
pick 90b08a2 Add A.txt file
pick a2ef353 Add B.txt file
pick 848ddfa Add C.txt filepick 90b08a2 Add A.txt file
pick 848ddfa Add C.txt file
pick a2ef353 Add B.txt file

Squashování commitů
Squashování commitů (tzn. spojení dvou commitů do jednoho). Pro příklad budeme chtít, aby se commity s B.txt a C.txt spojili dohromady. Použijeme k tomu „squash“ nebo písmeno „s“ Je nutné myslet na to, že squashuju novější commit do staršího. Pokud uvedu „squash“ u C.txt, budou se squashovat B.txt a C.txt. Pokud bych uvedl „squash“ u B.txt, bude se squashovat A.txt a B.txt.
pick 90b08a2 Add A.txt file
pick a2ef353 Add B.txt file
pick 848ddfa Add C.txt filepick 90b08a2 Add A.txt file
pick a2ef353 Add B.txt file
s 848ddfa Add C.txt filePo uložení se nám otevře textový editor. Výsledný text pak představuje commit message, kterou bude mít nově vzniklý commit složený ze dvou.
# This is a combination of 2 commits.
# This is the 1st commit message:
Add B.txt file
# This is the commit message #2:
Add C.txt fileAdd B.txt and C.tsx
Fixupování commitů
Fixup není vlastně nic jiného, než squash. Mějme situaci následující situaci.

Máme nějaký commit v historii, kdy jsme udělali chybu a chceme ho opravit. Můžeme udělat nový commit a přes interaktivní rebase tento commit přesunout a squashnout je do sebe. To je poměrně hodně úkonů na tak jednoduchou věc jako je oprava commitu 🙂 Můžeme využít fixup. V našem případě má commit hash „93909ec26a68ba46bb8482ef434e3329e92aba4e“. Nemusíme nutně kopírovat celý hash (to platí i pro všechny ostatní příkazy, kde používáme hash nějakého commitu). Postačí, když jeho začátek bude dostatečně dlouhý na to, aby GIT poznal, o jaký commit se jedná.
$ git commit --fixup=[hash commitu který chceme opravit]
$ git commit --fixup=93909ec26a68baPo commitnutí fixupu se nám vytvoří commit, který má stejný popis jako commit, který chceme upravit s preffixem „fixup!“.

Nám nyní zbývá udělat interaktivní rebase s přepínačem „autosquash“.
$ git rebase -i HEAD~3 --autosquashPo zadání se nám objeví v textovém editoru následující:
pick 93909ec Some commit needs to be fixuped
fixup 458f988 fixup! Some commit needs to be fixuped
pick 075684e Some other commitVidíme, že fixup commit se správně zařadil tam kam má (tzn. za původní commit, který chceme opravit). Po uložení se nám fixup automaticky přidal k původnímu commitu a tak historie vypadá úplně stejně, jako na začátku.

Tipy pro práci s GITem
Atomicita
Každý commit by měl být atomický. Atomicita znamená, že každý commit obsahuje právě jednu změnu. Definice toho, co je jedna změna záleží do určité míry na „citu“: programátora. Pokud budu přidávat novou funkcionalitu, mohu si celou feature rozdělit do několika kroků.
Mějme e-shop, který zobrazuje profil pro uživatele a zadání je, aby se uživateli nově v profilu zobrazoval součet hodnot všech objednávek. Feature je jasná, teď k implementaci:
- nejdříve vytvořím logiku na součet cen všech objednávek (např. nějaký SELECT z DB)
- poté tuto logiku „připojím“ ke controlleru a budu tak posílat data do šablony
- následně tuto informaci zobrazím zákazníkovi (s nějakým pěkně vytvořeným designem 🙂 )
Správně by každý z těchto bodů měl být v samostatném commitu, ale dokážu si představit že první dva body nebo dokonce všechny tři někde uvidím i v jednom. Je to problém? Asi ne, ale je dobré vědět, jak je to správně a pak dělat odchylky než naopak 🙂
Pojmenování (popisování) commitů
Ze všeho nejdříve je nejdůležitější si uvědomit, PROČ je popsání commitu důležité. Kromě toho, že je díky tomu možné pracovat s historickým vývojem projektu, správně popsaná commmit message plní funkci popisu kódu. To znamená: Co se změnilo a pokud to z toho není na první pohled zřejmé, tak i PROČ se to změnilo.
Např. PHPStorm umožňuje přes akci „Annotate with Git Blame“ zobrazit historii každé řádky, včetně datumu, jména autora a právě commit message.
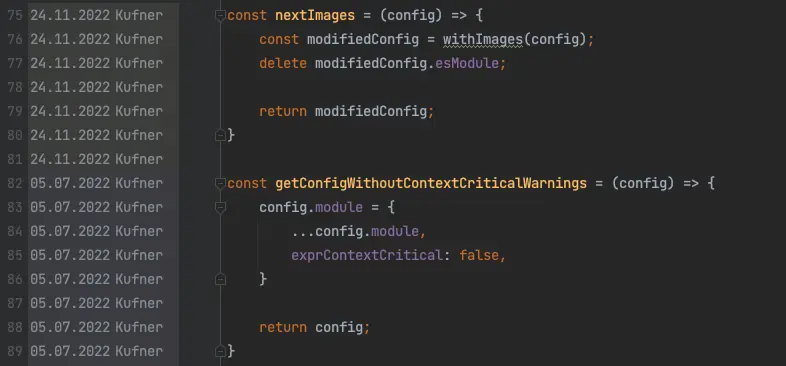
Doporučená pravidla:
- Commit messages pište tak, že nejprve popíšete v první řádce stručně co commit obsahuje. Pokud je potřeba zprávu doplnit, odřádkujte formou nového odstavce a tam popište funkcionalitu detailněji.
- Řádky v commit message by neměly mít více než 72 znaků (kvůli čitelnosti v nástrojích, jako je např. GitLab)
- Odstavce oddělujte novým řádkem (to platí i pro první řádek a popis)
- Pište v 5. pádu a ideálně anglicky – nikdy nevíte, kdo na projektu bude pracovat za pár let. Tedy např. „Add CPU resources“, „Implement calculating special price for christmas event“ namísto „
Adds CPU resources“, „Fixed XY method“… - Při popisu zkuste být co nejvíce konkrétní (já vím, občas to bolí :D). Nicméně přiznejme si, že „Fix function for computing special christmas price when 2 days left“ řekne více než „Fix function“ 🙂
Pojmenování větví
Zdrojů k pojmenovávání větví je na internetu mnoho. Zde zkusím napsat pár tipů, které mě osobně vyhovují a přijde mi praktické se jich držet.
- Pokud máte nějaký ticketovací systém (např. Jira nebo Redmine) a ticket na kterém pracujete má své číslo, uveďte ho v názvu větve (a ideálně i názvu merge requestu).
- Pokud na projektu pracuje více vývojářů, prefixujte větev svými inicály. Velice to oceníte v případě různého našeptávání větví
- V názvu mějte alespoň základním způsobem popsaný ticket, který tato větev řeší. Dost výhodné je to zejména v případě, kdy se v závislosti na názvu větve vytváří merge-request – ušetříte si práci 🙂
Tedy např. „mk-2452-implement-new-product-detail-gallery„